Multimodal RAG lets you search an image database with text or images, then generate intelligent responses. It combines three technologies: embedding model, vector database, and multimodal LLM.
How the Landscape Changed in 7 Years
Around 2019, we built data processing systems RAG with numpy, scikit-learn, RabbitMQ, and PostgreSQL. Today, the ecosystem shifted completely – instead of manually coding workflows and managing message queues, we reach for dedicated frameworks, ready-made APIs, and managed cloud services. PostgreSQL evolved (pgvector for vectors), but specialized vector databases now dominate.
Architecture – 3 Core Components
Instead of building from scratch, integrate existing tools:
- Embedding model – converts images to vectors (numerical representation)
- Vector database – stores and rapidly searches vectors
- Multimodal model – analyzes images and generates responses
Step-by-Step Implementation
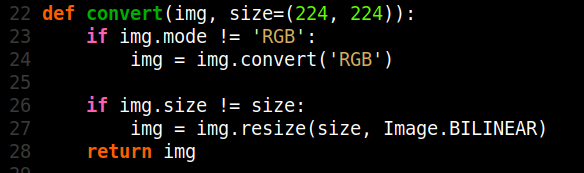
Step 1: Image Vectorization
Convert each image to embeddings using a vision-capable model:
- OpenAI CLIP – open model, 512–1024 vector dimensions
- Jina AI v4 – new multimodal embedding (April 2026), native image storage
- Google Multimodal Embeddings API – GCP integration
- LLaVA – open-source, local deployment support
Each image becomes a vector of numbers you can manipulate mathematically.
Step 2: Storage in Vector Database
Save vectors with metadata (file path, name, date):
Step 3: Search (Retrieval)
User asks: “Photos from mountain vacation”
- Query is converted to vector (same model as step 1)
- Search algorithm (usually cosine similarity) finds k-nearest vectors
- Returns top-3 or top-5 images matching the query
Step 4: Generation (Augmentation)
Multimodal model receives retrieved images + user question. Available options:
Cloud / API
- Gemini 3.5 Flash – released May 19, 2026, 4x faster than previous models, cheaper (4x lower cost than Gemini 3.1 Pro) Google CloudMarkTechPost
- Claude Opus 4.7 – latest (April 2026), improved visual analysis and coding
- GPT-5.5 – released April 23, 2026, OpenAI’s newest model WikipediaOpenAI
Local / Open-source
- LLaVA – lightweight model, runs on mid-range GPUs
- Qwen VL – Chinese model, strong text-in-image understanding
- InternVL2 – fast and accurate, multilingual support
- Llama 3.2 Vision – Llama series with built-in vision
- MobileVLM – optimized for mobile devices
Model returns natural responses grounded in retrieved images.
Real-World Use Cases
E-commerce & support
Customer uploads photo of broken product → system finds matching catalog item → generates repair guide or purchase link.
Private photo assistant
Search thousands of photos in natural language: “Where was I a year ago?”, “Dog photos at the beach”.
OCR & data extraction
Scan invoices, charts, technical schematics as PNG/JPG. RAG finds related documents, LLM extracts specific numbers and tables.
Automatic tagging
New images automatically analyzed, categorized, and described for SEO or social media posts.
Smart document search
Logo recognition, text extraction, schema comparison – all within one workflow.
Cost Optimization – New in 2026
Model Routing – dynamically route queries to SLMs (Small Language Models) for cheap operations, LLMs for complex tasks. Cost reduction: 50-75x cheaper than LLM APIs – monthly bills from $3,000 to $127. DEV CommunityIterathon
Prompt Caching – instead of loading all tool definitions, system retrieves them dynamically based on query. Build Fast with AI
Top SLMs for 2026:
- Microsoft Phi-3 – 3.8B params, strong reasoning Intuz
- Google Gemma 2 9B – best quality-to-size ratio
- Meta Llama 3.2 – best for edge/mobile
Tools to Get Started
| Tool | Type | Link |
|---|---|---|
| LangChain + Jina AI | Framework | langchain.com |
| LlamaIndex | Orchestration | llamaindex.ai |
| Hugging Face Models | Models | huggingface.co/models |
| Ollama | Local Models | ollama.ai |
| BentoML | SLM Deployment | bentoml.com |