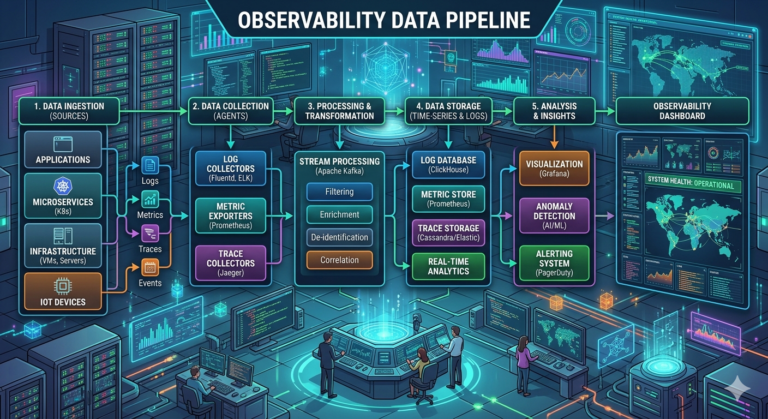
Popularny Trend: Migracja na Datadog
W ostatnich latach obserwujemy wyraźny wzrost liczby firm, które przechodzą na Datadog. Ten trend nie ogranicza się już tylko do monitorowania infrastruktury mikrousług – serverless, VM czy kontenerów. Coraz więcej organizacji chce rozszerzyć Datadog na pełne pokrycie observability, obejmując monitoring i alerty dla całych data pipeline’ów.
Jednym z kluczowych problemów, które Datadog rozwiązuje, jest widoczność opóźnień w przetwarzaniu danych. Firmy chcą wiedzieć, dlaczego pipeline’y czekają na zasoby i jak długo rzeczywiście trwają procesy. To pytanie jest często bolączką dla zespołów zajmujących się inżynierią danych lub mikroserwisami.
Rosnące Zapotrzebowanie na SRE
Równolegle z wzrostem zainteresowania Datadog obserwujemy wzrost zapotrzebowania na specjalistów od SRE (Site Reliability Engineering). Trend ten przypomina ten wokół sztucznej inteligencji – choć być może nie tak widoczny, to zdecydowanie realny. Firmy zdają sobie sprawę, że obserwacja systemów wymaga dedykowanych umiejętności.
Dlaczego Firmy Wybierają Datadog zamiast Alternatyw?
Datadog vs Grafana
Pierwszym powodem migracji z Grafany jest ułatwione śledzenie relacji między usługami. Grafana wymaga znacznie więcej pracy przy pokrywaniu traces między komponentami systemu. Datadog oferuje tutaj przewagę – relacje między usługami są mapowane automatycznie lub z mniejszym wysiłkiem.
Datadog vs Sentry
W porównaniu z Sentry’em Datadog wymaga większego nakładu pracy na konfigurację. Sentry pozwala deweloperom na prosty pattern „set and forget” – szczególnie w aspekcie śledzenia wyjątków. Jednak Sentry nie jest taki modyfikowalny – brakuje mu flexibilności przy definiowaniu niestandardowych reguł alertów i metryk.
Atrakcyjny Dashboard i Koszt Ukryty
Jednym z głównych motywatorów migracji na Datadog jest jego dashboard. Na pierwszy rzut oka wydaje się, że ma wszystko, co potrzebne do pełnej observability – metryk, logów, traces – i wszystko jest logicznie ułożone w jednym miejscu.
Rzeczywistość okazuje się jednak bardziej złożona. Po kilku tygodniach wdrożenia firmy odkrywają problem: koszty szybko rosną. Datadog rozliczany jest za objętość danych, a przy monitorowaniu milionów zdarzeń dziennie rachunek może być znaczący. Wiele firm musi wtedy dokonać cięć w zakresie monitorowania.
Rekomendacja: Buduj na Logach
Aby uniknąć eksplozji kosztów, rekomendujemy budować fundamenty observability na podstawowej jednostce – logach. Logi powinny być podstawowym źródłem metryk i alertów. To podejście jest bardziej ekonomiczne i daje większą kontrolę nad tym, co faktycznie monitorujesz.
Pamiętaj jednak o jednym ważnym elemencie: log traceability. Jest to mechanizm pozwalający na śledzenie pojedynczego żądania przez cały system – od pierwszego punktu wejścia aż do ostatecznej odpowiedzi. Każdy log związany z danym żądaniem zawiera wspólny identyfikator (trace ID), który umożliwia rekonstrukcję pełnej ścieżki przetwarzania.
Słownik Terminów Observability
- Trace – zapis pełnej ścieżki żądania przez system; pokazuje czasy odpowiedzi poszczególnych usług
- SRE (Site Reliability Engineering) – dyscyplina łącząca inżynierię oprogramowania z operacjami; zespoły SRE dbają o niezawodność i wydajność systemów
- Observability – zdolność zrozumienia wewnętrznego stanu systemu na podstawie jego zewnętrznych outputs (logi, metryki, traces)
- Log Traceability – możliwość połączenia logów z różnych usług w jedną spójną historię żądania
- Span – pojedyncza operacja w ramach trace; reprezentuje pracę wykonaną przez jedną usługę
- Metric – miernik; liczba agregowana w czasie (np. średnia, percentyl)
- Alert – powiadomienie aktywowane gdy metryka przekroczy próg
- Atrybuty Logów – dodatkowe pola danych dołączone do logu (np. user_id, request_id, status_code); ułatwiają filtrowanie, wyszukiwanie i korelację logów