Popular Trend: Migration to Datadog
In recent years, we’ve observed a clear uptick in companies migrating to Datadog. This trend is no longer limited to monitoring microservices infrastructure—serverless, VMs, and containers. More and more organizations want to expand Datadog to provide full observability coverage, including monitoring and alerting for entire data pipelines.
One of the key problems that Datadog solves is visibility into data processing delays. Companies want to know why pipelines wait for resources and how long processes actually take. This question is often a pain point for data engineering teams or those working with microservices.
Rising Demand for SRE
Alongside the growing interest in Datadog, we’re seeing increased demand for SRE specialists (Site Reliability Engineering). This trend echoes the one around artificial intelligence – though perhaps not as visible, it’s definitely real. Companies are realizing that system observability requires dedicated expertise.
Why Do Companies Choose Datadog Over Alternatives?
Datadog vs Grafana
The first reason for migrating from Grafana is Datadog’s simplified tracking of relationships between services. Grafana requires significantly more work when covering traces between components. Datadog offers an advantage here—service relationships are mapped automatically or with minimal effort.
Datadog vs Sentry
Compared to Sentry, Datadog requires more setup effort. Sentry allows developers to follow a simple “set and forget” pattern—especially for exception tracking. However, Sentry is not as customizable – it lacks the flexibility for defining custom alert rules and metrics.
Attractive Dashboard and Hidden Costs
One of the main motivators for migrating to Datadog is its dashboard. At first glance, it seems to have everything needed for full observability—metrics, logs, traces—all logically organized in one place.
Reality proves more complex. After a few weeks of deployment, companies discover the issue: costs rise quickly. Datadog charges based on data volume, and when monitoring millions of events daily, the bill can be substantial. Many companies then need to make cuts in their monitoring scope.
Recommendation: Build on Logs
To avoid cost explosion, we recommend building your observability foundation on the basic unit—logs. Logs should be your primary source for metrics and alerts. This approach is more economical and gives you greater control over what you actually monitor.
Remember one important element: log traceability. This is a mechanism that allows you to track a single request through your entire system—from entry point to final response. Every log related to a given request contains a shared identifier (trace ID) that enables you to reconstruct the full processing path.
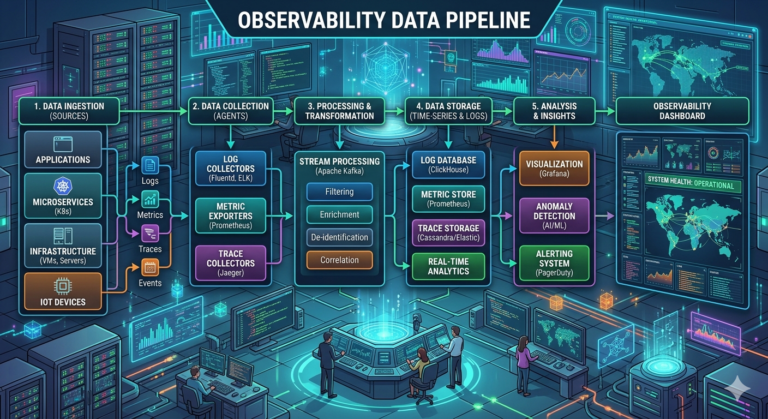
Observability Terminology
- Trace – a record of the full path a request takes through the system; shows response times for individual services
- SRE (Site Reliability Engineering) – discipline combining software engineering with operations; SRE teams ensure system reliability and performance
- Observability – the ability to understand a system’s internal state based on its external outputs (logs, metrics, traces)
- Log Traceability – the ability to connect logs from different services into one coherent request history
- Span – a single operation within a trace; represents work done by one service
- Metric – a measurement; a number aggregated over time (e.g., average, percentile)
- Alert – a notification triggered when a metric exceeds a threshold
- Log Attributes – additional data fields attached to a log (e.g., user_id, request_id, status_code); facilitate filtering, searching, and correlating logs